
Suno AI を使ってみたものの、いつも似たような曲調になってしまう。
AI Vocal ( AIボーカル ) の日本語が不自然で、間奏や曲の展開が思い通りにならない。そんな悩みを抱えていませんか。
生成AI による Music Generation ( 音楽生成 ) はただのガチャだと諦めるのは早計と言えます。
最新の v5.5 の仕様を深く理解し、 Style Prompt ( スタイルプロンプト ) 、 Meta Tag ( メタタグ ) 、作詞の記号という3つの要素を正しく操れば、プロ顔負けの狙った楽曲を意図的に作り出すことが可能です。
本記事では、この Generation Tool で自分の世界観を100%表現するために、私が普段行っている具体的な Prompt ( プロンプト ) 技術と調声の裏技をすべて公開します。
この攻略法を実践し、 AI 任せのランダム生成から今日で卒業しましょう。

完成イメージを先に見たい方は、 AI アニメ MV ( Music Video ) の制作実例もあわせてご覧ください。
狙った曲調を引き出す Style Prompt の黄金法則
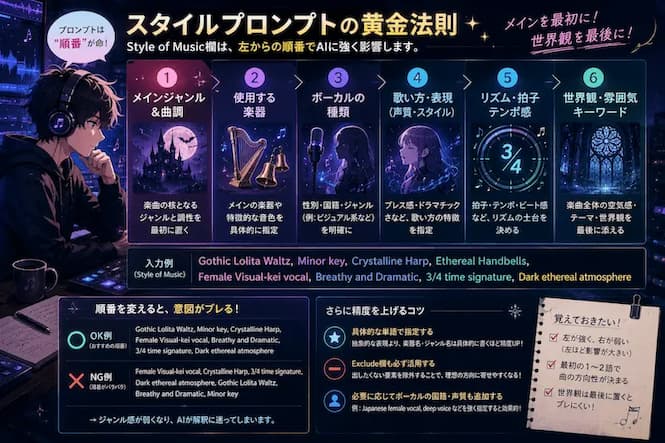
楽曲の方向性を決める際、1つの Genre ( ジャンル ) に絞るか、複数ジャンルをミックスするかを最初に決めてください。
複雑で Originality ( オリジナリティ ) のある楽曲を作りたい場合、複数ジャンルのミックスが効果的です。
その際、最も重要になるのが Prompt を入力する順番となります。
ジャンルミックスは順番が命
画像生成 AI などと同様に、この Generative AI も前方に配置したワードほど強く影響を受ける性質を持っています。
例えば、ゴスロリ風のワルツを主軸にヴィジュアル系要素を入れたい場合、以下のような順番で Style of Music 欄に入力してみてください。
Gothic Lolita Waltz, Minor key, Crystalline Harp, Ethereal Handbells, Female Visual-kei vocal, Breathy and Dramatic, 3/4 time signature, Dark ethereal atmosphere
メインとなるジャンルと曲調を先頭に置き、次いで使用する Instrument ( 楽器 ) 、 Vocal の指定、歌い方の特徴、 Rhythm ( リズム ) 、そして世界観という型で構成するのがコツです。
劇的に精度を上げる裏技と Personalize の罠
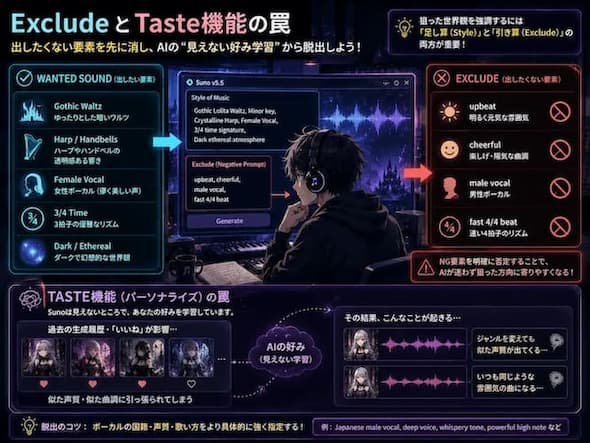
狙った世界観を強調するためには、 Exclude ( ネガティブプロンプト ) 欄の活用が欠かせません。先ほどのゆったりとしたワルツを作る際、 Exclude 欄に upbeat, cheerful, male vocal, fast 4/4 beat と入力し、出したくない要素を明確に否定してください。
また、 System ( システム ) 内部には見えない部分で User の好みを学習する Personalize Function ( パーソナライズ機能・Taste機能 ) が働いている可能性があります。
ジャンルを変えても似たような声質のボーカルが出てくる場合、過去の Generation ( 生成 ) 履歴の影響を受けている可能性が高いです。
全く違うボーカルを引き出したい時は、 Style Prompt でボーカルの国籍や声質(例: Japanese male vocal, deep voice など)をより強く、具体的に指定する必要があります。
楽曲の展開を自在に操る Meta Tag と情景描写の魔法
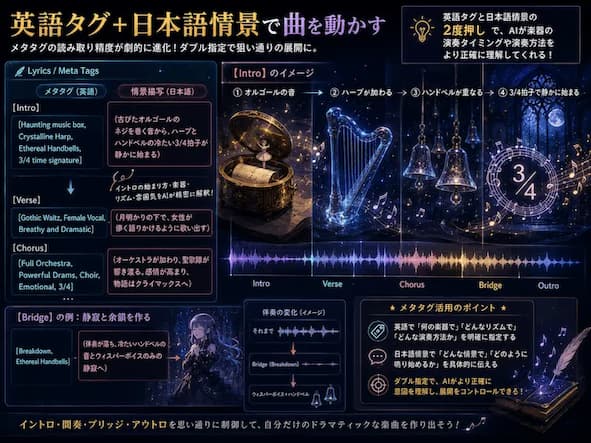
曲の展開を Control ( コントロール ) するには、 Lyrics ( 歌詞 ) 欄に入れる Meta Tag ( メタタグ ) が鍵を握ります。
v5.5 への Update ( アップデート ) 以降、この Meta Tag の読み取り精度と解釈が劇的に進化しました。
日本語情景描写のダブル指定テクニック
Intro ( イントロ ) や間奏を狙い通りに動かしたい時、英語の Meta Tag だけでなく、日本語の情景描写を丸括弧で囲んで追記する手法が非常に強力です。
例えば、曲の冒頭に以下のように入力してみてください。
[Intro]
[Haunting music box, Crystalline Harp, Ethereal Handbells, 3/4 time signature]
(古びたオルゴールのネジを巻く音から、ハープとハンドベルの冷たい3/4拍子が静かに始まる)
また、間奏で静寂を作りたい場合は、以下のように指定します。
[Bridge]
[Breakdown, Ethereal Handbells]
(伴奏が落ち、冷たいハンドベルの音とウィスパーボイスのみの静寂へ)
英語タグと日本語情景の2度押しをすることで、 AI が楽器の演奏タイミングや演奏方法をより正確に汲み取ってくれるようになります。
AI Vocal に感情と Rhythm を宿らせる作詞・調声のコツ
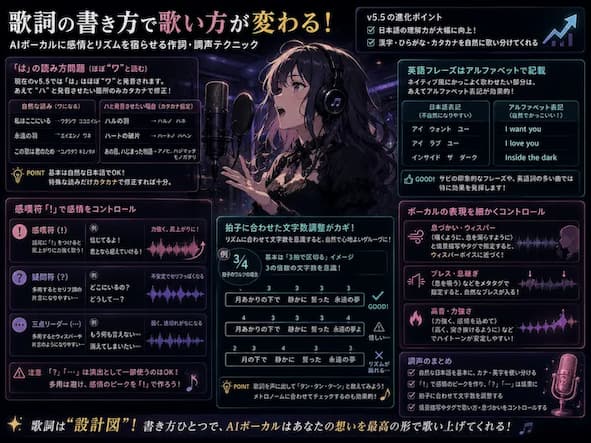
以前の Model ( モデル ) では全編カタカナで歌詞を書く必要がありましたが、 v5.5 では漢字や日本語の理解力が飛躍的に向上しました。
そのため、基本的には自然な日本語のまま入力する方が、より感情豊かな歌い方になります。
「は」の読み方問題とカナ・アルファベットの使い分け
v5.5 で大きく変わったのが助詞の「は」の扱いです。
以前はハとワの発音が混在していましたが、現在はほぼワと読んでくれます。
したがって、あえてハと発音させたい特殊な箇所のみカタカナで修正すれば問題ありません。
また、英語のフレーズを Native ( ネイティブ ) 風にかっこよく歌わせたい部分は、あえてアルファベットで表記する工夫を取り入れてみてください。
拍子に合わせた文字数調整と感嘆符の隠しコマンド
聴きやすい楽曲にするためには、 Rhythm に合わせた作詞が不可欠です。
例えば3拍子のワルツであれば、3拍子に乗る文字数を意識して歌詞を構築すると、非常に心地よい Groove ( グルーヴ ) が生まれます。
さらに、歌い方の感情を Control するテクニックとして感嘆符「!」の活用をおすすめします。
語尾に!をつけると、高い確率で Vocal が尻上がりに力強く歌い上げてくれるはずです。
また、疑問符「?」や三点リーダー「…」を多用すると、セリフのような片言の日本語になりやすいため、意図的な演出以外では使用を避けるのが無難でしょう。
音割れ・ Noise 対策と Creator としての向き合い方
音に強いこだわりがある場合、 Exclude 欄で音域を指定するなどの対策も有効です。
しかし、 Platform ( プラットフォーム ) の Server ( サーバー ) 状況や生成タイミングによって、どうしても Noise ( ノイズ ) が入るなどの AI 特有の現象は避けられません。
これに対してすべてを完璧に修正しようとするのではなく、あえて Glitch ( グリッチ ) 系のジャンルに落とし込んでノイズを目立たなくさせるか、 AI の味として許容する Creator ( クリエイター ) としての割り切りも重要になってきます。
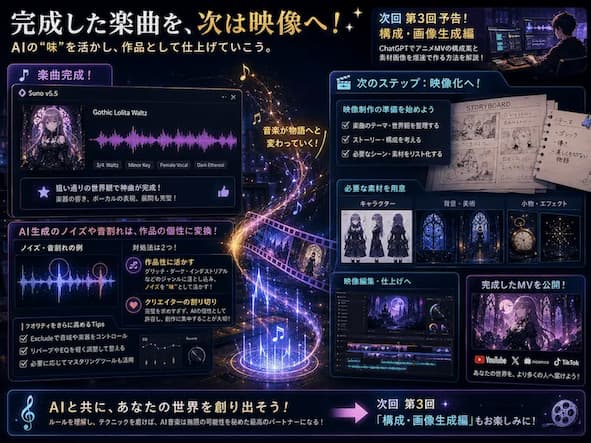
まとめ:楽曲が完成したら、次は映像化の準備へ!
今回は、この Music Generation Tool の v5.5 仕様を活かした Prompt 作成から、 Meta Tag による展開の制御、そして細かな調声のテクニックまでを解説しました。
これらの Know-how ( ノウハウ ) を組み合わせることで、あなたの世界観を色濃く反映した神曲が必ず生み出せるはずです。
楽曲が完成したら、次はいよいよ映像化の Step に入ります。
次回の第3回では、完成した楽曲に合わせて、 ChatGPT を活用してアニメ MV の構成案と素材画像を爆速で作る方法を詳しく解説していきます。
全体の Roadmap ( ロードマップ ) をまだ確認していない方は、まずは第1回の記事をご覧ください。
なお、今回ご紹介したプロンプト技術をすべて注ぎ込み、私が本ツールで Generation ( 生成 ) したオリジナル楽曲の Quality ( クオリティ ) は、 YouTube チャンネル BR_Re-cords で公開中の MV で確認できます。
細かな楽器のニュアンスやボーカルの感情表現など、 AI Music の最前線をぜひあなたの耳で確かめてみてください。次回の構成・画像生成編もどうぞお楽しみに。


コメント